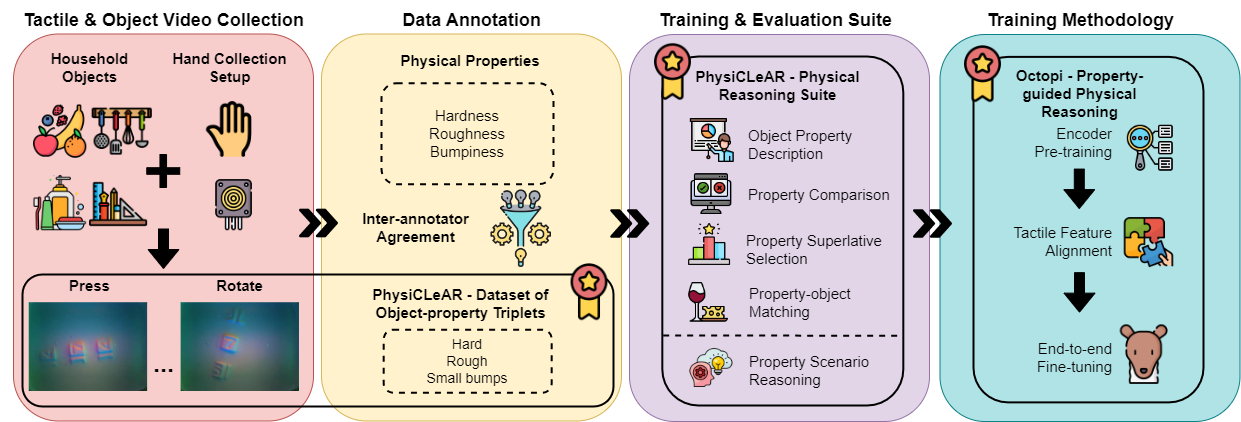
We introduce PhysiCLeAR, a new dataset containing GelSight tactile videos of everyday household objects. The videos are collected by hand with two exploratory procedures, pressing and rotation, and annotated for three useful physical properties: hardness, roughness and bumpiness. PhysiCLeAR leverages the videos and annotations to create five language-driven physical description and understanding tasks. We train and evaluate Octopi, a large VLM, on PhysiCLeAR for tactile-grounded physical understanding and scenario reasoning.
Our experiments show that Octopi is able to predict physical properties from the tactile videos accurately and use the physical properties to reason about and resolve scenarios.
A new GelSight tactile dataset with property diversity, object diversity, and material diversity for three useful physical properties: hardness, roughness and bumpiness. It contains 74 everyday household objects and 408 tactile videos. The videos are annotated by three annotators for the physical properties.










The physical object properties selected, along with their descriptions and semantic categories.

PhysiCLeAR provides physical property labels for tactile descriptions and physical reasoning across three physical properties. We further compare against existing datasets across three diversity measures. Property diversity refers to whether there are objects in the dataset that vary across the three properties we selected: hardness, roughness and bumpiness. Object diversity indicates whether there is more than one type of object in the dataset. Material diversity indicates the number of different materials in the dataset.

PhysiCLeAR also contains five physical description and understanding tasks. We give each task's motivation and indicate whether they are used for Octopi's training and/or evaluation. Specific details about the prompt setup of each task can be found in our paper.

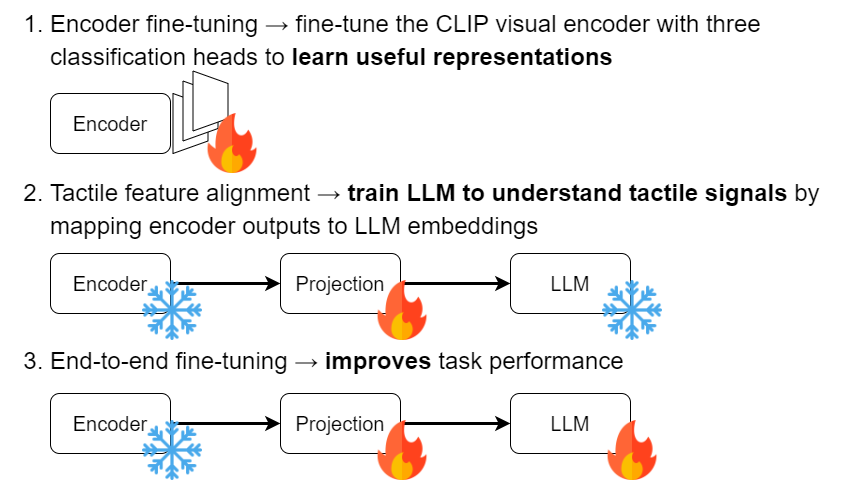
Octopi comprises three trained components: 1) tactile input encoder, 2) projection module, and 3) LLM, similar to prior LVLM models. We use the CLIP (ViT-L/14) visual encoder to extract feature representations from input tactile videos. The encoder's output is then mapped to the LLM's word embedding space using a projection module (two linear layers). Finally, the LLM forms the language understanding component of Octopi. We use the open-source LLaMA-based LLM, Vicuna v1.5, recognized for its dialogue capabilities. Language embeddings are derived through tokenization and then Vicuna's word embedding layer, with <tact_start> and <tact_end> being newly trained word embeddings indicating the start and end of a tactile frame sequence from a single tactile sensor.

Octopi training is done in three steps. The fire emoji indicates that the component is trained while the snowflake emoji indicates that it is frozen.
Octopi-7b and Octopi-13b perform above the random baseline for object property predictions and have similar performance to Fine-tuned CLIP + Classification, indicating that Octopi can be used for object property prediction. Octopi-13b has a higher combined accuracy (i.e. all three physical properties are correctly predicted for a given object) when compared to Octopi-7b, suggesting there are performance gains with larger LLMs for tactile signal grounding.

During scenario reasoning, we do not provide ground-truth property descriptions. Our experiments show Octopi-7b and Octopi-13b perform above the random baseline, indicating that Octopi can be used for scenario reasoning. Furthermore, leveraging object properties (i.e. Object Property Description) significantly improves scenario reasoning for Octopi, which supports our overall hypothesis that leveraging these properties is helpful for these tasks. Interestingly, we observe that the 7b model marginally outperformed the 13b model. More details about the scenarios can be found in our paper.



@article{yu2024octopi,
title={Octopi: Object Property Reasoning with Large Tactile-Language Models},
author={Yu, Samson and Lin, Kelvin and Xiao, Anxing and Duan, Jiafei and Soh, Harold},
journal={arXiv preprint arXiv:2405.02794},
year={2024}
}
 Octopi
Octopi
